
Generated by ChatGPT
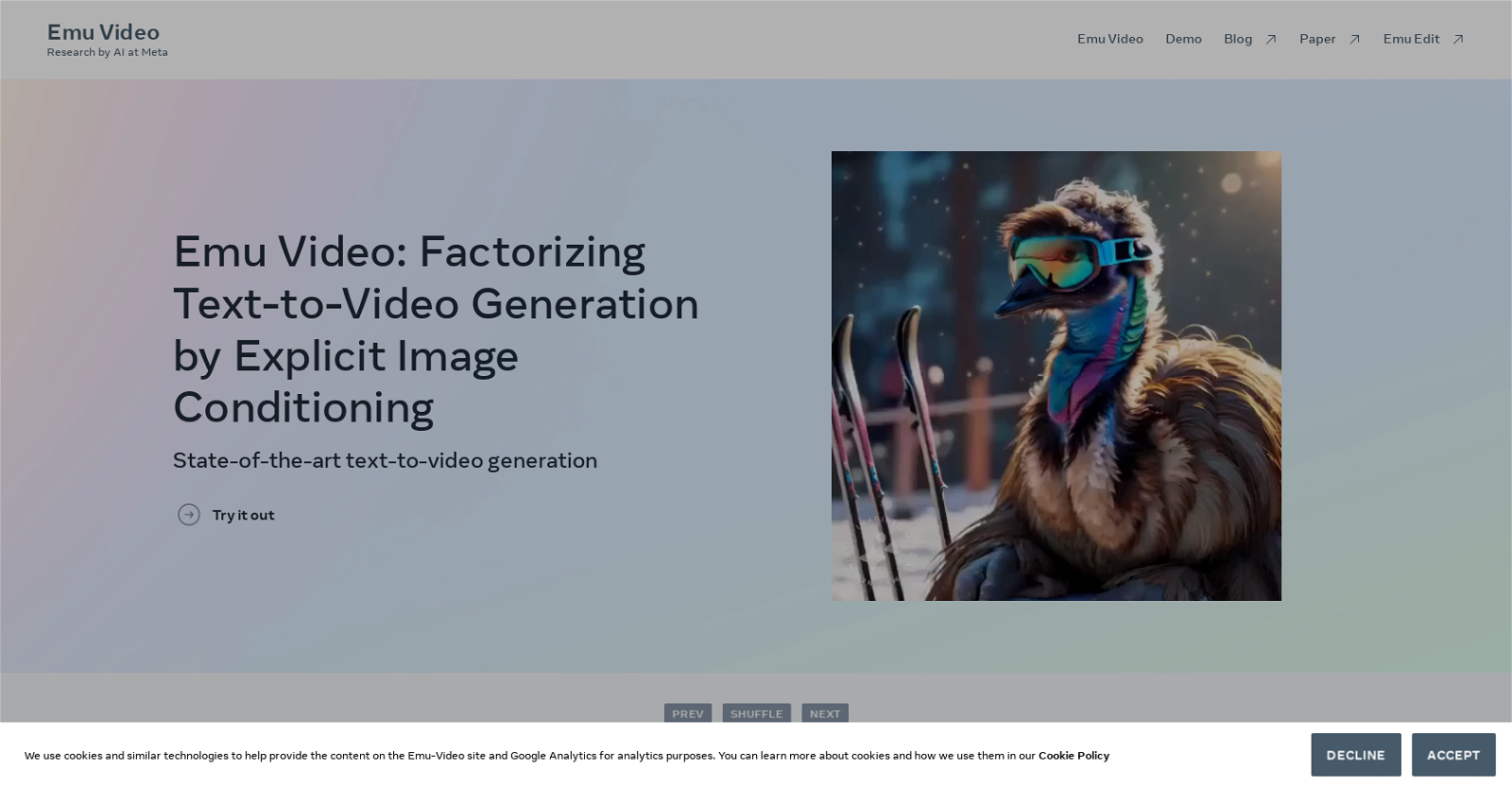
Emu Video is a tool that focuses on text-to-video generation using explicit image conditioning. It employs diffusion models to factorize the generation process into two steps: generating an image based on a text prompt and then generating a video based on the prompt and the generated image. This factorized approach enables efficient training of high-quality video generation models. Emu Video stands out from previous methods that require a deep cascade of models by only needing two diffusion models to generate 512px, 4-second-long videos at 16fps.The tool provides state-of-the-art results in text-to-video generation when compared to other models such as Make-a-Video (MAV), Imagen-Video (IMAGEN), Align Your Latents (AYL), Reuse & Diffuse (R&D), Cog Video (COG), Gen2 (GEN2), and Pika Labs (PIKA). Human raters have selected Emu Video’s 512 pixels, 16 frames per second, 4-second-long videos as the most convincing ones in terms of quality and faithfulness to the given prompt.Authors of this tool include Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra, with equal technical contributions coming from Rohit Girdhar and Mannat Singh. The tool acknowledges the support of multiple collaborators who assisted in the work, providing data and infrastructure. Emu Video also maintains privacy and cookie policies, which can be viewed on their website.
Create high-quality videos with AI, 20x faster and cost-efficient.
Generated video marketing for ecommerce.
Enhanced mobile video editing with advanced technology.
Made pro music videos sans editing or prod knowledge.
Generated video creation from text.
Generated lifelike speech and video content.
Scripted video creation and editing with teleprompter.
Create videos from written text input.
Quick video creation for different purposes.
Converts text to video.
Video personalization for sales & marketing.
Video creation for training & communication
Effortlessly turn product images into viral videos.
Create stunning videos in seconds, not hours
Customized videos with cloned voices and faces.
Enhanced video editing for polished content creation.
Video creation for content creators and businesses.
Platform to create high-quality, personalized videos.
Create videos instantly from prompts.
Styled videos without mentioning brand names.
Teleprompter-guided video recording.
Automated social media video creation.
Produced human-presented videos for diverse goals.
Create professional videos in minutes with PlayPlay.
Enhanced video creation: quality and subtitles.
Video production for startups & enterprises
Custom music videos w/ visuals & matching tones.
Generated video animates customized text formats.
Video creation & sharing platform
Creates camera-free engaging videos.
Video generation for marketing, sales, and training.
Bring Your Vision To Haiper Reality
Professional-looking video creation for different uses.
Generates stable diffusion model videos from images.

Automated creation of videos without filming or editing.
Convert text into customized spoken videos with avatars.
Automated video creation from written text.
Generates videos with different prompts and styles.
Empowering your creativity with Lens Studio.
Tailored videos with digital avatars.
Created social media-ready video advertisements.
Video creation for product launches
Create diverse video edits.
Transforming language models into video generators.
Multilingual videos with lip-sync & live dubbing.
Automated video creation from blog content.
URLs transformed into captivating videos.
Generate lifelike videos and digital models with Skriva.
Personalized e-commerce video marketing.
Voice-to-video creation without coding expertise.
Suggested YouTube content ideas.
Turning text into stylized videos.
Generative video content studio.
Video generator for content creators.
High-quality videos generated with advanced tech.
Actor-less, affordable high-quality video production.
The creation of videos from still images.
Efficient video messaging enhances collaboration.
Simplify video creation with AI.
Creation of videos from text input.
Create videos from text with ease.
Transform text and images into mesmerizing videos.
Business videos with custom avatars & voiceovers.
Video editing with customizable templates.
Mobile app for easy video creation.
Creating and hosting a video knowledge base.
Turn Text into Engaging Videos
Create incredible video content in seconds with AI.
Video creation from plain text in multiple languages.
Your videos, your voice...any language
Global video AI generation for content creation.
Generated comic videos.
System that creates videos from text prompts.
Create stunning videos & animations from text prompts.
Video generation for creators
Generate engaging videos from text content rapidly.
A magical space where text transforms into video.
Supercharge your YouTube Workflow with Twip!
Improve your experience with our personalized advertising services.
Text and image-based video generation.
Generate pro videos from text using video spokespersons.
Content creators generate videos from text.
Auto video creation from written text & media resources.
Creates marketing videos
Video generator with custom music and style options.
Personalized short videos with sounds.
The most advanced text to video AI.
Created captivating videos with recommended footage.
Customizable templates for professional videos.
Auto-generated diverse avatars for video from text.
Software for bringing motion into digital worlds.
Supercharge your video creation with Ozone.
Efficient multimedia platform for video creation.
Created realistic videos.
Craft on-brand & engaging videos in minutes using AI.
Generated videos for training.
Generate likey human videos in impossible formats.
Text to vid with auto graphics, music & captions.
Personalized videos for efficient communication.
Video creation & editing with effects & templates.
Automated content creation for social media & platforms.
Transform blog content into social videos.
Creation of engaging videos for various industries.
Custom avatars, dynamic voiceovers, compelling videos
Unleash your AI Art creativity in just 3 seconds with web-based ComfyUI.
Leverage generative AI without any coding skills.
Video management solution for business transformations.
Creating visuals to tell stories.
Create videos with actors, little expertise.
Create AI-generated videos from text prompts effortlessly.
Automated video creation for businesses and individuals.
Custom commercials from imported business details.
Create viral TikToks and Reels from text to video with AI
Written ideas to captivating videos
Generate a stunning video from just a text prompt or a speaking clip.
Customized video creation with effects and avatars.
Personalized marketing videos.
Video production with synthetic actors.
Create viral videos in seconds with AI
Easily make engaging videos online.
Generates unique music videos from text prompts online.
Effortlessly capture, edit iOS videos.